
|
||
| Menu | VisualVoice / Outline | |
|
About Artistic Vision People Teams Contact us Publications Media Images/Movies Opportunities Related Links |
Future Work - OutlineUp to this point, the talking face has been implemented with a one-to-one mapping of phonemes to facial expressions - the user specifies a static image for each phoneme, and the face is driven by the same data used to generate speech. The next phase of development would allow multiple images for each phoneme, according to a list of different expressions. This brings in two main requirements: i) The performer must be able to communicate these expressions to the system ii) Map files must be able to specify different vizeme files for different expressions The first requirement is already filled - if the user creates a dictionary with multiple expressions, corresponding map files will contain an entry for each phoneme & each expression, like EE happy, EE sad, I happy, I sad, to each of which one vizeme file can be associated. In order to fulfill the second requirement, the system needs to recognize different expressions based on input data in performance mode. This means that the user must train the system to differentiate expressions. The system must then be able to determine expression probabilities in a similar way that it determines phoneme probabilities, and use both to map facial expressions. The following three figures elucidate the progress of the DIVA system; the first shows the system as of may 2008, the second shows additions for the talking face up to this point, and the third outlines additions for future work. 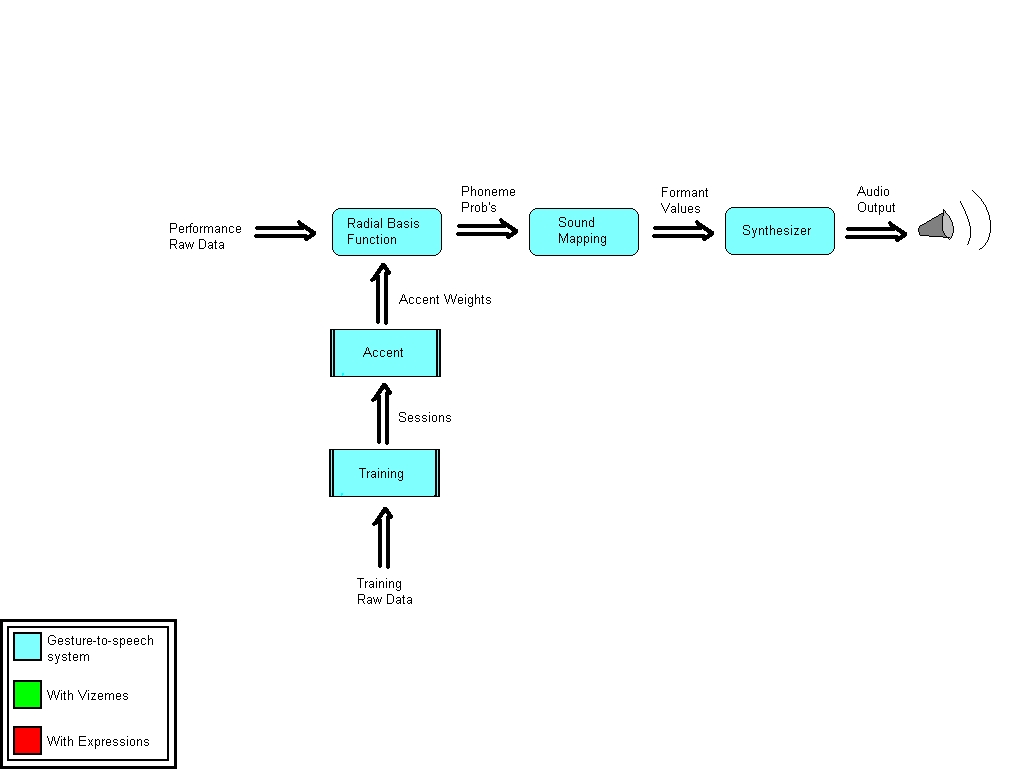 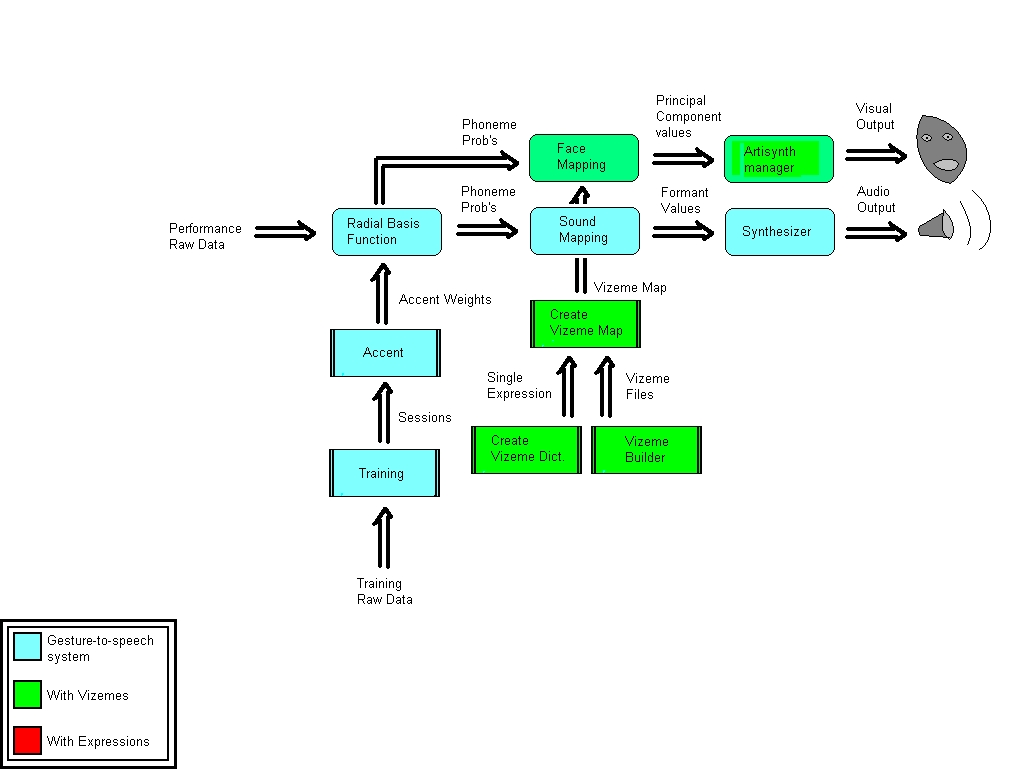 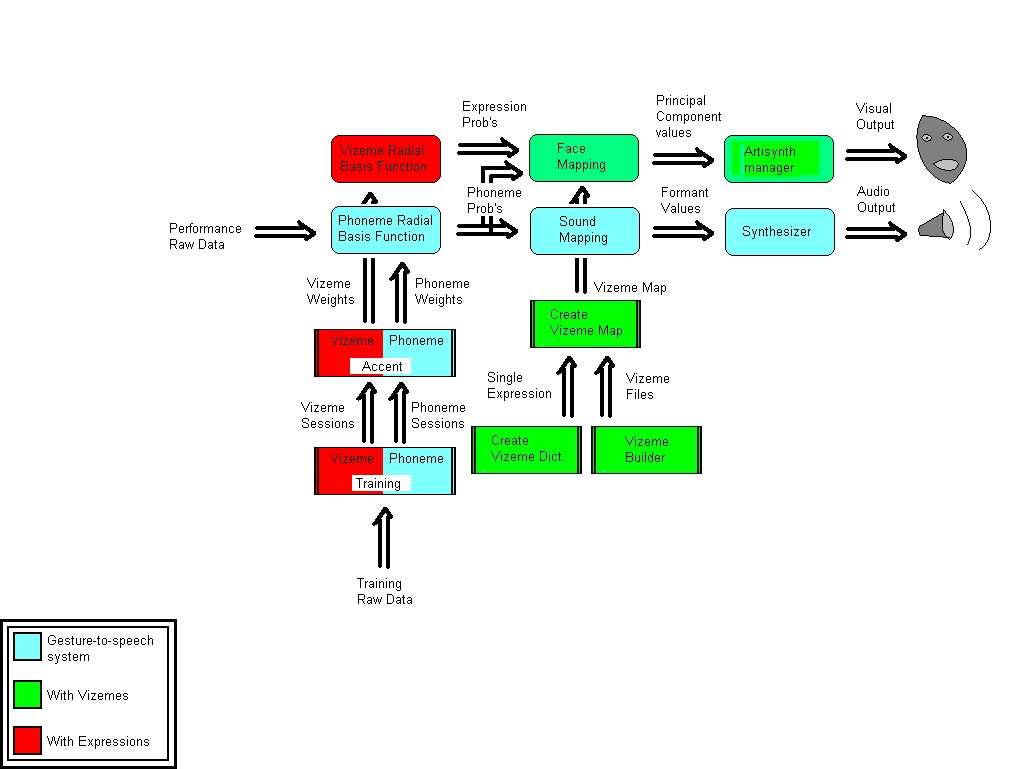 From this last diagram it can be seen that additional functionality will be required in the following areas: i) Training / CreateAccent - these interfaces will need to be split up into phoneme / vizeme modes, to allow the user to train the system for different expressions as well as different phonemes. It is recommended that the expression be based upon rotation of the performer's arm, such that it is independent of finger gestures (consonants) and hand position (vowels). ii) voiceMapping (subpatcher in the Perform window) - in order to convert performance data to expression values an additional mapping function is required, which will perform its calculation based on a "vizeme accent", similar to the existing accent, but based upon training sessions for expressions. iii) Artisynth Manager - an additional inlet for expressions is needed. Each combination of phoneme & expression will have a PC vector associated with it, and taken together the expression & phoneme probabilities will determine the strengths of each of these vectors. |
|
| View Edit Attributes History Attach Print Search Page last modified on August 26, 2008, at 09:25 AM | ||