
|
||||||||||||
| Menu | Demo / VocalTractModel | |||||||||||
|
Downloads Installation Instructions Learning Java Documentation Tutorials Update Log
Publications People Project Roadmap Code of Conduct |
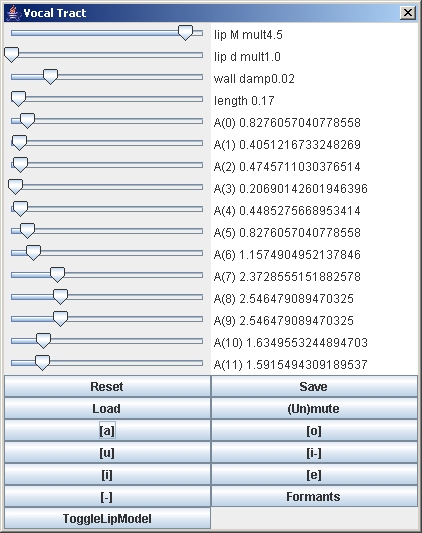
Vocal Tract ModelThe acoustics component models sound generation and propagation in the vocal tract (visible as a mesh) and the nasal tract (not visible). The glottal excitation can be generated with a Rosenberg parametric model or with the non-linear dynamic Ishizaka-Flanagan two-mass model. Both models can be controlled interactively through control panels:
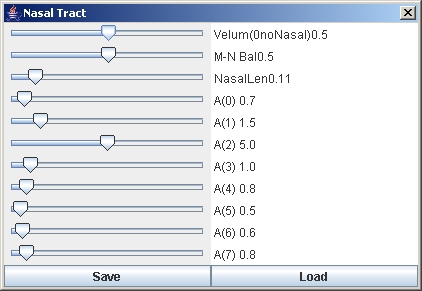
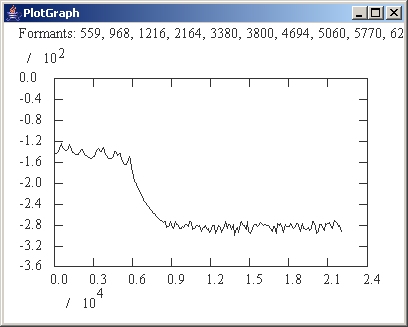
The acoustics of the vocal and nasal tracts is modeled using the linearized discretized Navier-Stokes equation, which is integrated in real-time and coupled to the dynamical two-mass model of the vocal chords. We have chosen this approach over the more usual Kelly-Lochbaum filter model in order to permit real-time length changes of the vocal tract. The resulting model is non-linear and produces pitched excitations as well as voiceless flow and chaotic excitations. Vowel shapes can be generated by clicking preset buttons in the vocal tract control panel which generate area functions for the six Russian vowels as described in "Acoustics Theory of Speech Production", Chapter 2.3, Gunnar Fant, 1970. The default area function for the nasal tract is taken from Dang and Honda JASA 96(4) 1994, p2093 fig.6, third subject. The nasal tract is assumed to be static and the only real-time variable affecting nasality is the velum position. The nasal tract can be configured with the nasal tract control panel. The vocal and nasal tract shapes can also be changed interactively with the sliders. Finally, for analysis purposes, the spectral response and the formants can be computed and displayed for any configuration. Noise is generated at the glottis and at the narrowest part of the vocal tract using the model described in Sondhi and Schroeter, IEEE Trans. Acoust. Speech and Signal Proc, Vol. ASSP-35, no. 7, 1987, pp. 955-967. Parameters can also be scripted with probes. We plan to couple the acoustics model to the tongue and jaw model, resulting in realistic control of the shape of the 3D airway and realistic speech. Videos
|
|||||||||||
| View Edit Attributes History Attach Print Search Page last modified on November 21, 2023, at 01:14 PM | ||||||||||||


{kind=link}
{kind=link}
{kind=link}